COMPLETEApr 2026
Hypothesis
When existing test files use older patterns, the agent will follow those patterns even when skills explicitly teach the newer ones. The codebase is a stronger signal than knowledge injection.Setup
The 2 Variants
Both variants have the same Spring testing skills installed globally.
Results (N=3)
Per-Run Breakdown
T2 Quality Breakdown
Behavioral Analysis
Despite identical quality scores, the two variants navigate the codebase differently.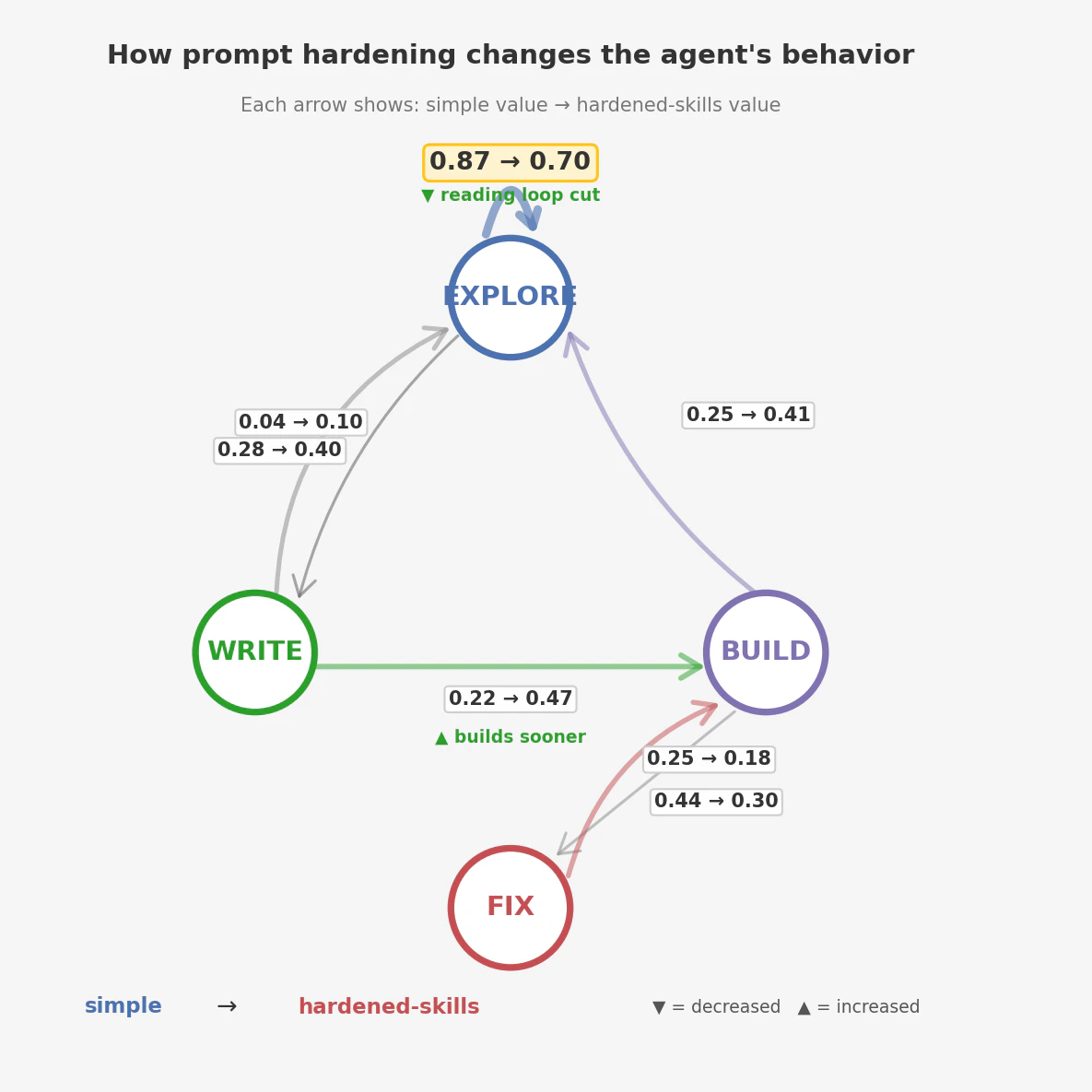
The Exemplar Effect: v2 vs v3
Key Findings
- The codebase is the agent’s primary teacher. Skills and prompts are secondary signals. If the existing code demonstrates older patterns, the agent will reproduce them — even when it has explicit knowledge of the better approach.
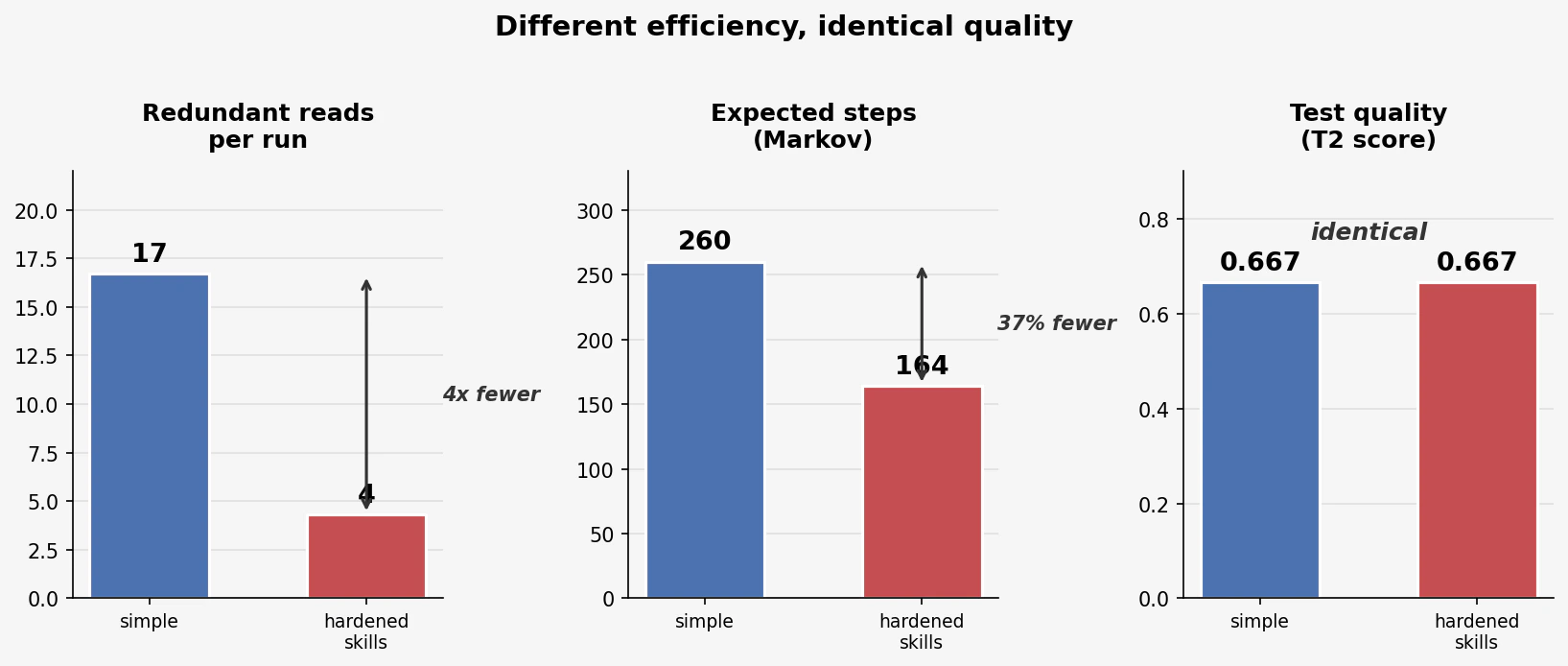
- Quality ceilings come from exemplars, not prompts. T2 = 0.667 across all 6 runs. Two variants, three runs each, identical quality score. The ceiling moved when the existing tests changed (v2 vs v3), not when the prompt changed.
- Efficiency gains are still real. 37% fewer expected steps, 4x fewer redundant reads, half as many reading-loop cycles. Prompt hardening and skills make the agent faster — they just can’t make it better when the codebase says otherwise.
- Fix the code, not the prompt. The highest-leverage intervention for agent quality is updating the exemplars the agent will see.
What Comes Next
v4: Fix the exemplar — but not by hand. A separate “Boot best-practices upgrade” step — skill-driven, focused, run before the test-writing agent starts. Fix the code the agent will imitate, then let it imitate. Prediction: T2 rises to ≥0.85.Resources
Experiment Repo
Variant configs, analysis scripts, raw traces
Blog: When You Come to a Fork in the Code
Narrative walkthrough of the exemplar effect
Results Report (PDF)
Full quantitative results with figures and tables
v2 Experiment
The previous experiment — skills vs knowledge bases with zero existing tests