COMPLETEMar 2026
Hypothesis
Structured skills (SkillsJars) outperform flat knowledge injection — not because they contain more knowledge, but because structure itself changes agent behavior. Pre-analysis (a mandatory exploration pass before writing code) further reduces wasted steps by front-loading understanding.Setup
The 7 Variants
Each variant adds one variable on top of the previous. This isolates the effect of each intervention.Results (N=3)
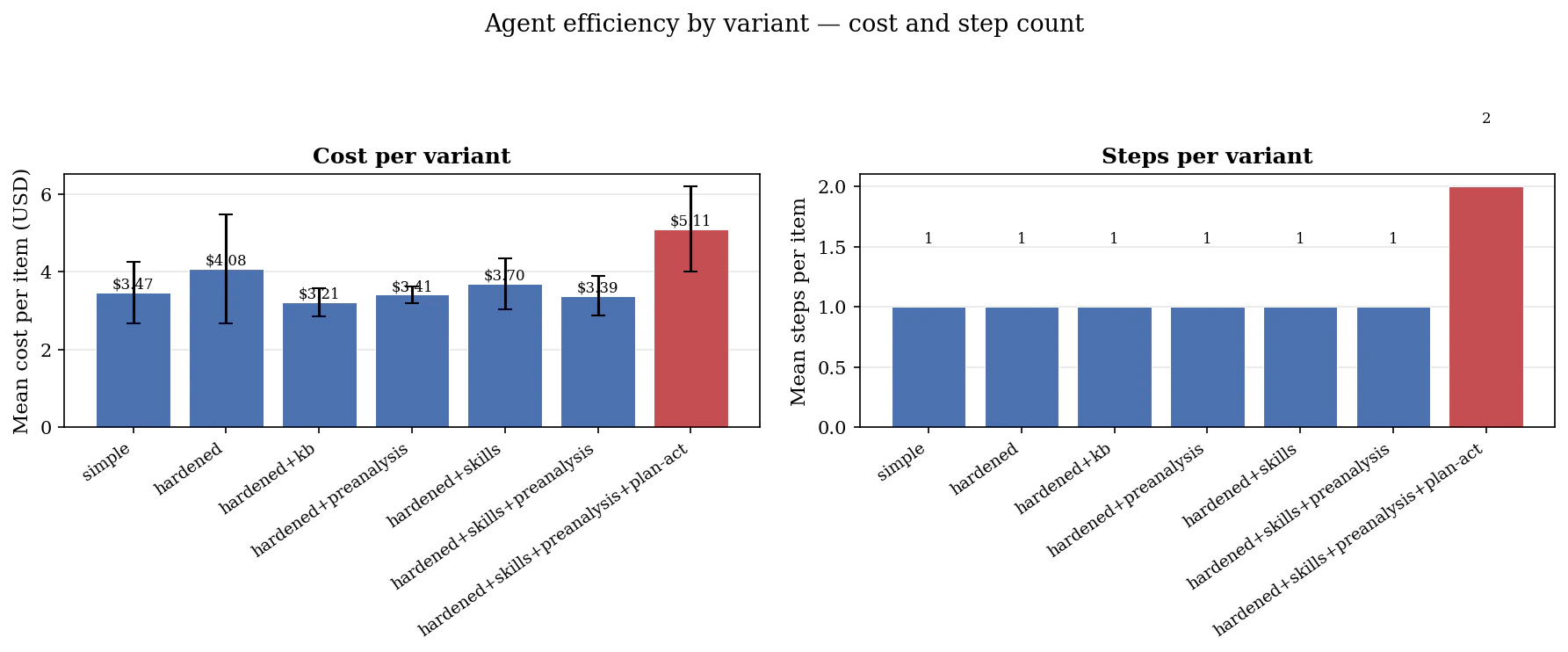
Key Findings
1. Prompt hardening is the biggest quality driver
simple → hardened: +0.067 quality, -6% steps. A free gain from structural discipline alone — no knowledge injection, just telling the agent when to stop and how to structure its work.2. Pre-analysis drives efficiency at a quality cost
hardened+preanalysis: -22% steps but quality drops to 0.789. The agent follows its pre-analysis plan too rigidly, missing edge cases it would have discovered through exploration. Same attention budget, worse allocation.3. Skills fix pre-analysis’s quality regression
hardened+skills+preanalysis: -31% steps AND quality = 0.850 (matches hardened). Skills give the agent the right vocabulary for each step, so it doesn’t waste attention discovering patterns. Best tradeoff in the experiment.4. KB is a pure efficiency play on known codebases
hardened+kb: -24% steps, quality flat. The knowledge base eliminates JAR inspection cycles (the agent no longer needs to discover Spring Boot 4 import changes). On novel codebases the effect should be larger.5. Plan-act is high variance
Highest quality ceiling (0.878) but also highest cost ($5.11) and rework spiral risk. The two-phase approach (deep exploration then sustained writing) occasionally gets stuck in fix loops.6. Markov model predicts step counts
Zero mean bias in leave-one-out cross-validation despite formal rejection of the first-order assumption. The model is wrong in theory but useful in practice.Behavioral Analysis
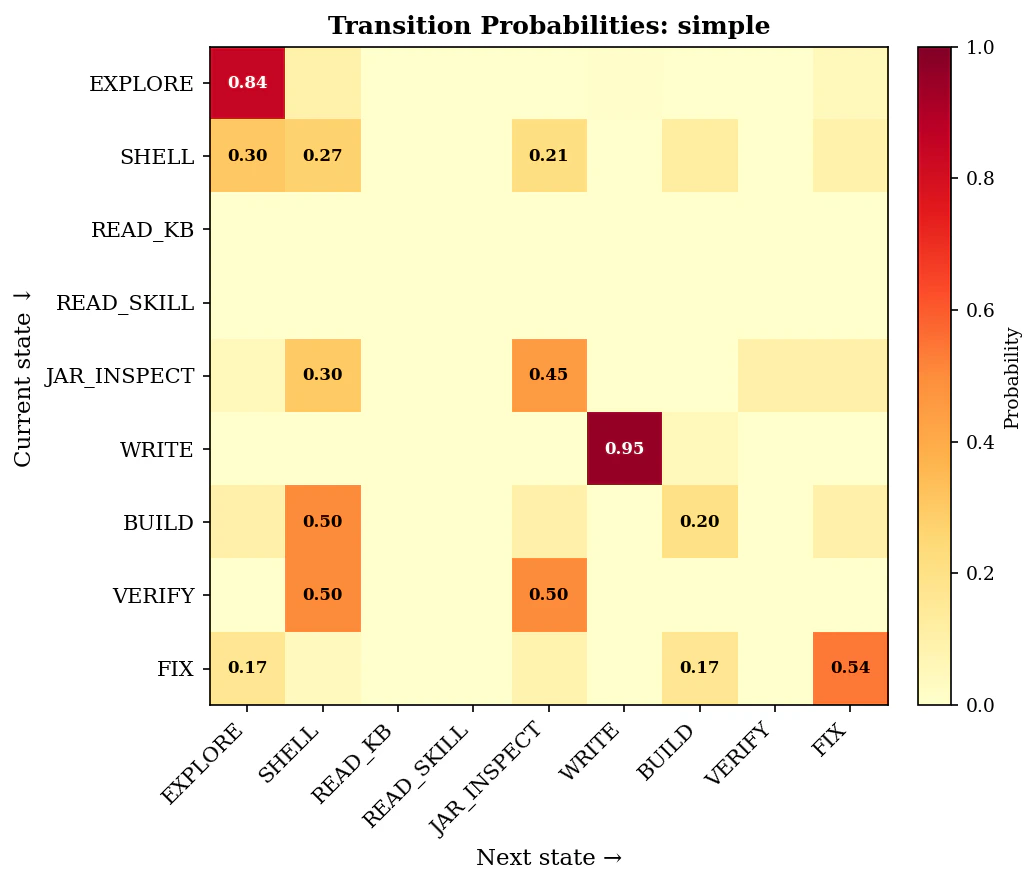
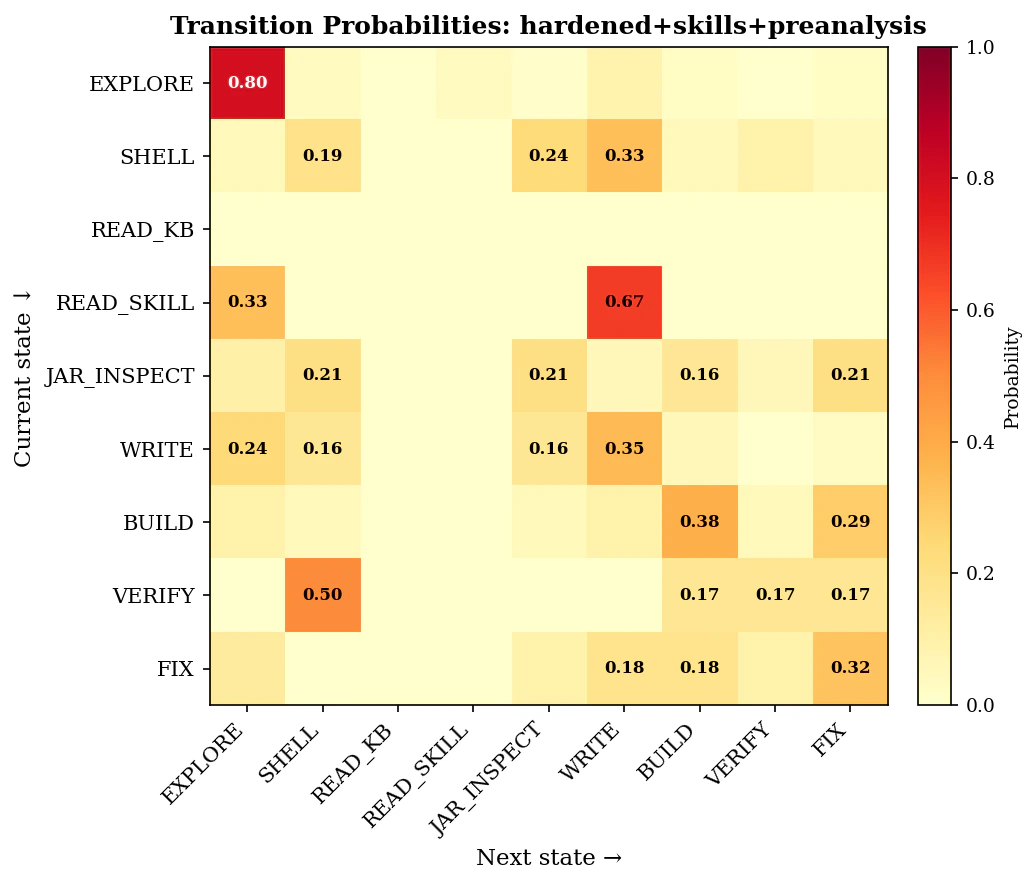
Every tool call across all 20 sessions was classified into one of 9 behavioral states using the Markov fingerprinting methodology. This reveals how variants differ, not just whether they produce different outcomes.Transition Probability Matrix
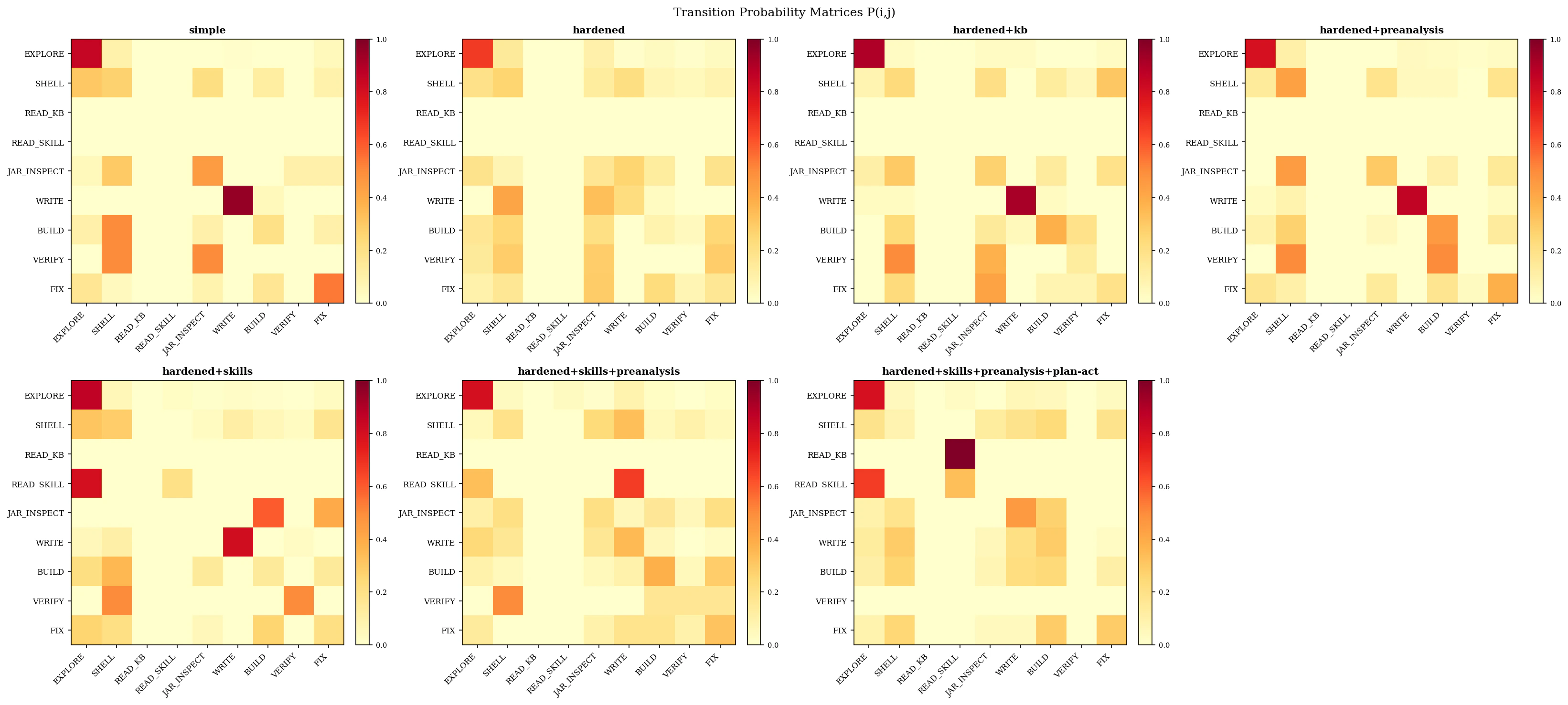
The JAR Cluster: Knowledge Friction
The most distinctive behavioral signature was the JAR_INSPECT cluster — the agent downloading and inspecting Spring Boot JARs to discover import paths that changed between Boot 3 and Boot 4.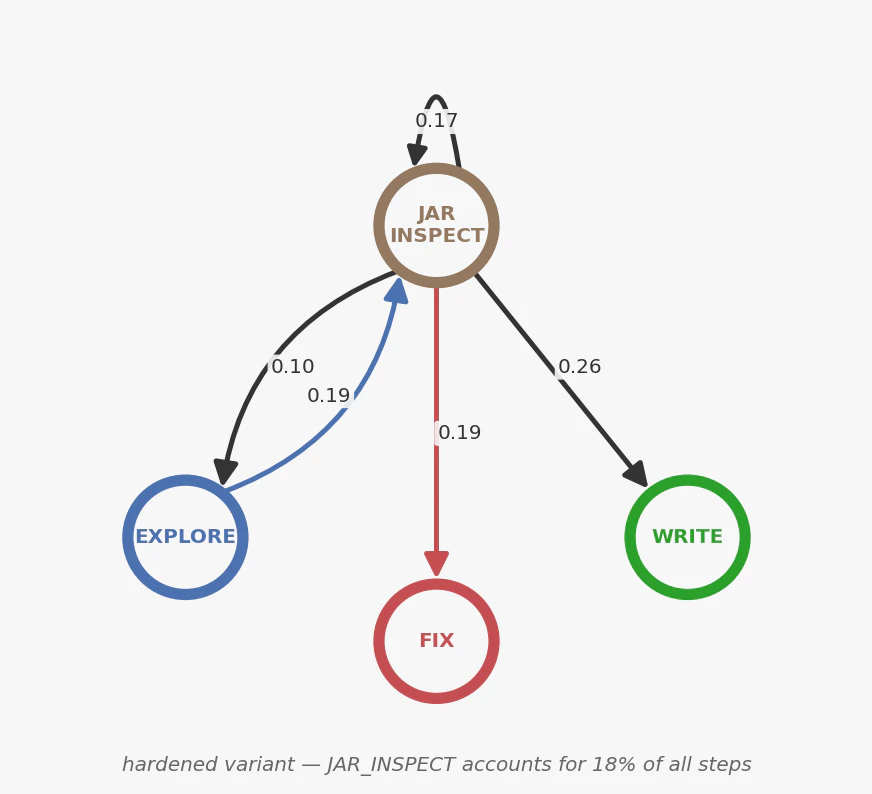
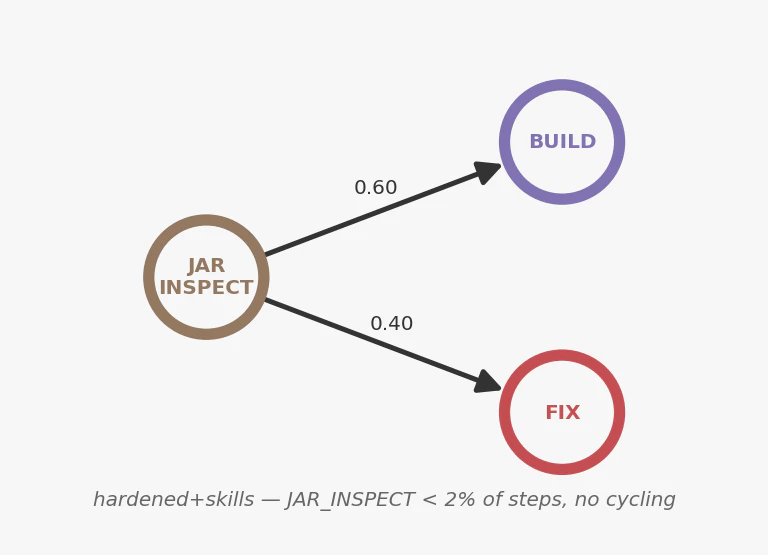
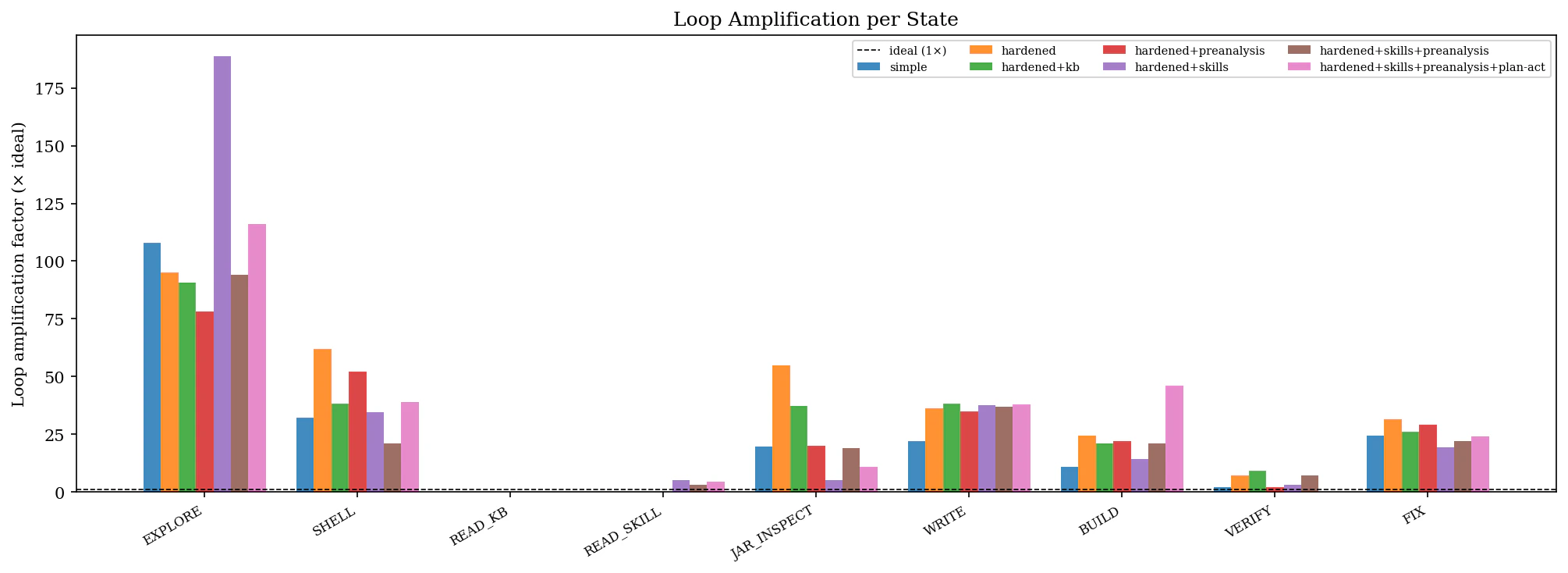
Loop Amplification
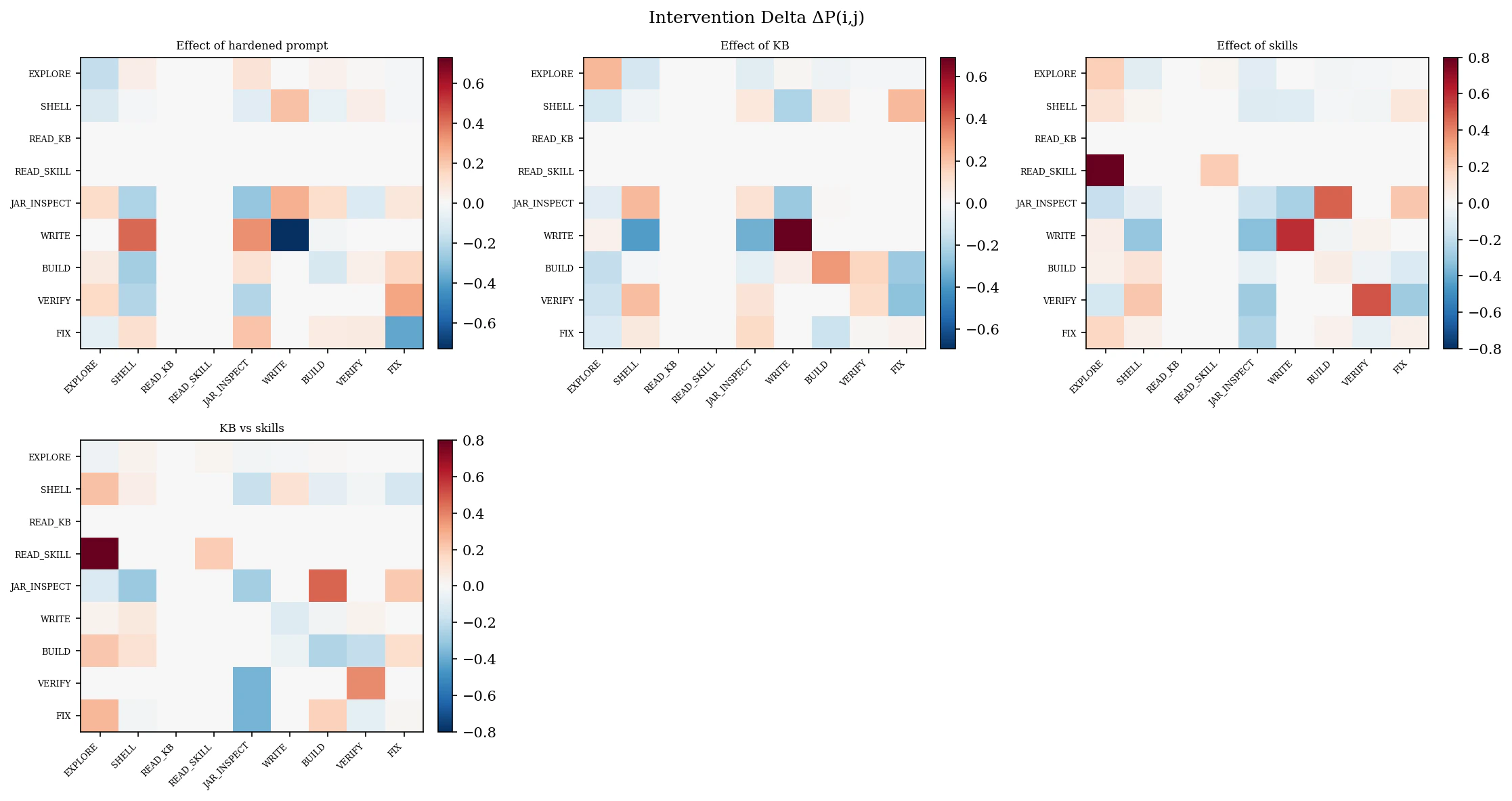
Intervention Deltas
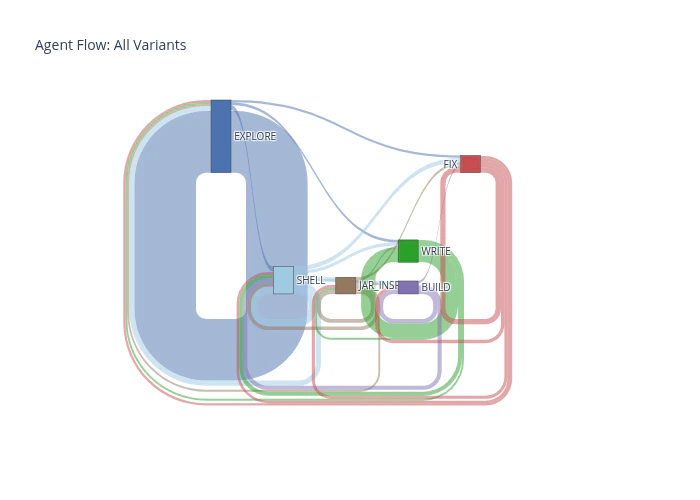
Sankey Flow Comparison
Behavioral Heatmaps
What Comes Next
The follow-up experiment (Code Coverage v3) tests what happens when the agent has skills but the existing codebase demonstrates older patterns. Spoiler: the codebase wins.Resources
Dataset & Traces (v2.0.0)
Full dataset download, variant configs, raw traces
Blog: I Read My Agent's Diary
Narrative walkthrough of the behavioral analysis
Results Report (PDF)
Full quantitative results with figures and tables
Reading Agent Behavior (PDF)
How to read agent behavioral traces — a casual explainer
v1 Baseline Experiment
The first experiment establishing the methodology
v3 Follow-up: The Exemplar Effect
What happens when existing code contradicts skill guidance